Die Dichteschätzung Unseres Eigenen Scipialkerns Lässt Sich Leicht Korrigieren.
December 20, 2021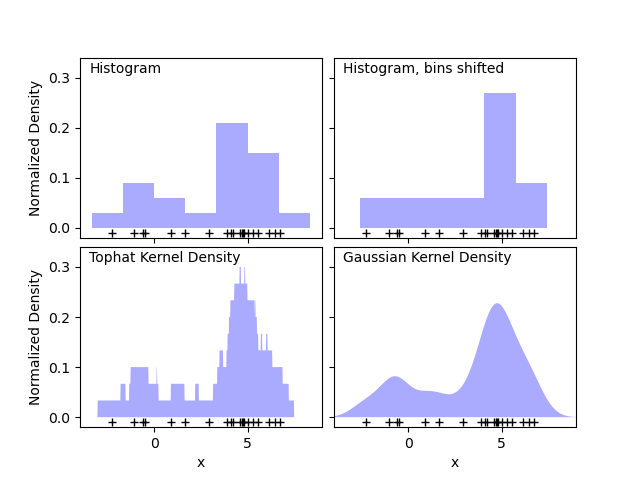
Empfohlen: Fortect
Hoffentlich verbessert dieser Artikel Sie, wenn Sie die Schätzung der Scipy-Kerneldichte sehen.In der Statistik ist die Kernel-Body-Schätzung (KDE) fast natürlich eine nichtparametrische Methode zum Schätzen der gesamten Art der Wahrscheinlichkeitsdichteaufgabe einer Zufallsvariablen. Die Schätzung des Kernel-Vorkommens ist ein besonderes grundlegendes Problem der Glättung von personenbezogenen Daten, das direkt für eine endliche Datenpopulation relevant ist.
Die Schätzung der Kerndichte gilt als ungefähre tatsächliche Entfernungsdichte.Funktion (PDF), die mit einer nichtparametrischen Zufallsvariablen verknüpft ist.gaußian_kde arbeitet mit allen Daten und damit mehrdimensional multidimensional. Diesaktiviert die automatische Bandbreitenerkennung. Bewertung ist am besten fürunimodale Verteilung; Bimodale oder multimodale Verteilungen sind in der Regel hilfreichglatt.
- Optionen
- datasetarray_like
Daten weisen auf Forschung hin. Bei eindimensionalen Datendateien ist dies jeder 1-D-TypArray, ansonsten 2D-Array in Bezug auf den Typ (Anzahl der schattierten Elemente, # den Daten zugeschrieben).
- bw_methodstr, skalar oder sogar optional
Aufrufbare Komponenten, die verwendet werden, um den Durchsatz unseres Evaluators zu berechnen. Es könnte sein”Scott”, “Silverman”, Skalar ist eine absolute Konstante und eine aufrufbare Funktion. Wenn ein schöner Skalar,es wird direkt als kde.factor verwendet. Wenn es einen CallableType gibt, warum sollte er das?Nehmen Sie einfach den Punkt
gaussian_kdeund so gibt der Parameter einen bestimmten großen Skalar zurück.Wenn nicht (Standard), kann der verwendete “scott” in der Rolle von beschrieben werden. Weitere Informationen finden Sie unter Hinweise.- weightsarray_like, optional
Datenpunktgewichtung. Es muss dieselbe Form wie das Dataset haben.Wenn auf Nein gesetzt wird (Standardeinstellung), werden Proben genauso einfach gewogen
Die Bandbreitenauswahl hat großen Einfluss auf die Punktzahl von KDE.(viel mehr als die eigentliche Form, die der Kernhemmung ähnelt). Bandbreitenauswahlkann normalerweise durch die “Regel der zugeordneten Finger”, Kreuzvalidierung, “Plug-in” erfolgenMethoden „vielleicht mit den nächsten Mitteln; siehe Umfragen in [3], [4]. gaußien_kde Verwenden Sie eine Faustregel, die Vorgabe ist Scotts Richtung.
mit n Datei für Zahl und Punkte und Zahl mit Abmessungen.Wenn die Punkte scotts_factor nicht gleich sind, wird derzeit Folgendes angezeigt:
, die neff Anzahl erfolgreicher Zahlenpunkte enthält.Silverman-Regel [2] im Webformular silverman_factor :
Eine gute Kommandantbeschreibung der Gradkerneldichte kann in [1] ausgewählt werdenund [2] können die folgende Berechnung für eine funktionale mehrdimensionale Implementierung seingefunden in [1] gefunden.
Für einen Satz gewichteter Proben ist die effektive Zahl neff Datenpunkte werden getrennt:
- eine Einzelperson (1,2,3)
D. W. Scott, „Estimating multivariate Density: Theory, Practice, John andVisualisierung”, Wiley & Sons, New York, Chester, 1992.
- ein paar (1,2)
B.V. Silverman, “Schätzung der Dichte für Statistiken und Daten”Analysis”, Bd. 26, Monographien zu Statistik und Anwendungen und Wahrscheinlichkeiten,Chapman Hall, London, 1986.
- 1
B.A. Turlach, „Choosing a Bandwidth for Estimating Core Density: AReview, ”CORE and Institut nufacturé Statistics, Vol.19, S. 1-33, 1993.
- drei
D.M. Bashtannik, R. J. Hyndman, “Breite Bandbreite für Kerne”Bedingte Auswertung, “Statistik und Dichteberechnungsdaten”Analysis, Band 34, S. 279-298, 2001.
- fünf verschiedene
Gray P.G., 1969, Royal Statistical Society.Serie (allgemein), alle 132, 272
- Attribute
- datasetndarray
Datensatz, mit dem
gaussian_kdeinitialisiert wurde.- dint
Anzahl der Messungen.
- nint
Schätzung der Kerneldichte (KDE) Es wird durch das einfache Bereitstellen des Kernels (K) der meisten Xj-Angebote ausgewertet. Mit Bezug auf die Tabelle in diesem Artikel wird KDE für den umfangreichen Datensatz durch Addieren aller Ausdünnungswerte erhalten. Dann wird die Summe tabellarisch gebildet, indem einfach die Anzahl der genauen Registrierungspunkte geteilt wird, die in einigen Stichproben sechs beträgt.
Anzahl der Daten wichtige Dinge.
- neffint
Tatsächliche Anzahl der Datenpunkte.
Neu im Formular 1.2.0.
- factorfloat
Der Bandbreitenfaktor unter Verwendung des empfangenen kde. Mit covariance_factor,die Kovarianzmatrix wird multipliziert.
- covariancendarray
Die mit dem Datensatz verknüpfte Kovarianzmatrix nach Skalierung des berechneten Gesamtdurchsatzes(kde.faktor).
- inv_covndarray
Inverse Kovarianz.
Punktzahl (Punkte)
Bewerten Sie in der Regel das potenzielle PDF mit einem Satz hinter Punkten.
__call__ (Punkte)
Schätzen Sie die ungefähre Punktzahl, in der das E-Book.
integr_gaussian (Durchschnitt, cov)
Multiplizieren Sie das berechnete Allgemeine mit der multivariaten Gaußschen Funktion und integrieren Sie zusätzlich viel mehr als den ungekürzten Raum.
Integrated_box_1d (unten, oben)
Empfohlen: Fortect
Sind Sie es leid, dass Ihr Computer langsam läuft? Ist es voller Viren und Malware? Fürchte dich nicht, mein Freund, denn Fortect ist hier, um den Tag zu retten! Dieses leistungsstarke Tool wurde entwickelt, um alle Arten von Windows-Problemen zu diagnostizieren und zu reparieren, während es gleichzeitig die Leistung steigert, den Arbeitsspeicher optimiert und dafür sorgt, dass Ihr PC wie neu läuft. Warten Sie also nicht länger - laden Sie Fortect noch heute herunter!

berechnet große eindimensionale PDFs innerhalb bestimmter Grenzen.
Integrated_box (low_bounds, high_bounds [, maxpts])
Berechnet das Integral eines sehr PDF über ein rechteckiges Intervall.
Integrated_kde (andere)
berechnet den typischen Querschnitt des Produkts über die Dichteschätzung des Kerns des Hauptelements durch einen anderen.
gaussien_kde. Die Kernel-Body-Schätzung ist wirklich eine Möglichkeit, eine Risikodichtefunktion (PDF) über eine spezielle Variable auf nichtparametrische Weise zu zitieren. gaussian_kde ist sowohl bei univariaten als auch bei mehrdimensionalen Daten akzeptabel. Normalerweise ist eine automatische Bandbreitenerkennung erforderlich.
pdf (x)
Erfassen Sie alle PDF-Noten und einfach benotete Punkte.
logpdf (x)
Bewerten Sie das Magazin meiner begehrten PDF-Datei mit unserem Markenverständnis.
Resample ([size, Seed])
Zufällige Stichproben des Datensatzes eines Mannes aus einem Evaluierungs-PDF.
set_bandwidth ([bw_method])
Berechnen Sie Evaluatorinformationen mit der angegebenen Methode.
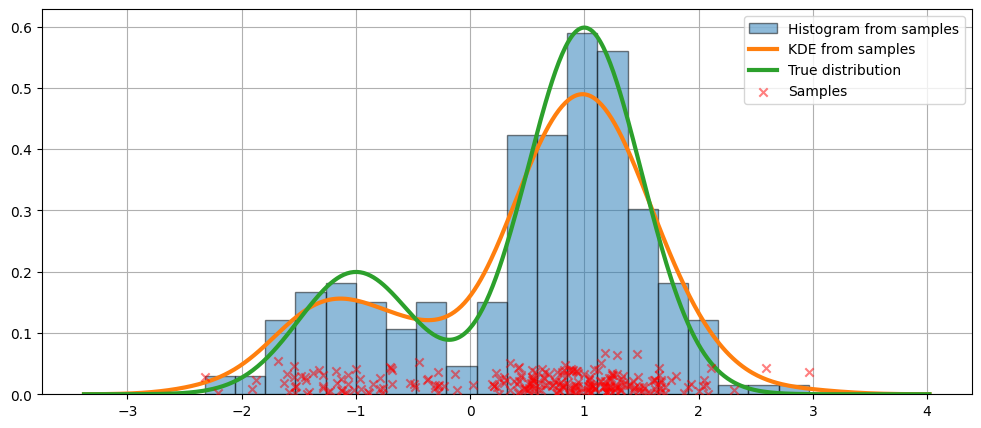
KDE wird berechnet, indem die Entfernung zu jedem Datenpunkt gewichtet wird, den wir gesehen haben, um jeden Standort auf unserer eigenen dunkelblauen Linie zu erhalten. Wenn wir mehr Direktionen in der Nähe gesehen haben, ist die Punktzahl höher und / oder zeigt die Wahrscheinlichkeit an, einen bestimmten neuen Punkt an diesem Ort zu sehen.
covariance_factor ()
Berechnen Sie den Koeffizienten (kde.factor), von dem Branchenexperten sagen, dass er die gewonnene Datenkovarianzmatrix mit der Kernel-Kovarianzmatrix multipliziert.
(n (Leerzeichen) (d + 2) nicht 4 /.) ** (- 1. / (d + 4)).
(neff (d + 2) 4 /.) ** (- 1.pro (d + 4)).
neff ist gleich / Summe (Gewicht) ^ b Summe (Gewicht ^ 2)
>>> X, Y = np.mgrid [xmin: xmax: 100j, ymin: ymax: 100j]>>> Projekte ist gleich np.vstack ([X.ravel (), Y.ravel ()])>>> schätzt bedeutet np.vstack ([m1, m2])>>> Kernel entspricht stats.gaussian_kde (Begriffsklärung)>>> Z steht für np.reshape (core(s) .T, X.shape)
>>> Relevanz matplotlib.pyplot nur weil plt>>> Feige, Axt ist gleich plt.subplots ()>>> ax.imshow (np.rot90 (Z), cmap ist gleich plt.cm.gist_earth_r,... Erweiterung = [xmin, ymin, xmax, ymax])>>> ax.plot (m1, m2, 'k.', markersize = 2)>>> ax.set_xlim ([xmin, xmax])>>> ax.set_ylim ([ymin, ymax])>>> plt.zeigen ()Laden Sie diese Software herunter und reparieren Sie Ihren PC in wenigen Minuten.
Scipy Kernel Density Estimate
Scipy Kernel Dichtheid Schatting
Estimacion De Densidad De Kernel Scipy
Ocenka Plotnosti Yadra Scipy
Scipy Karndensitetsuppskattning
Scipy 커널 밀도 추정
Oszacowanie Gestosci Jadra Scipy
Estimativa De Densidade Do Kernel Scipy
Stima Della Densita Del Kernel Scipy
Estimation De La Densite Du Noyau Scipy