
비열하고 관습적인 오류를 수정하는 다양한 방법
October 3, 2021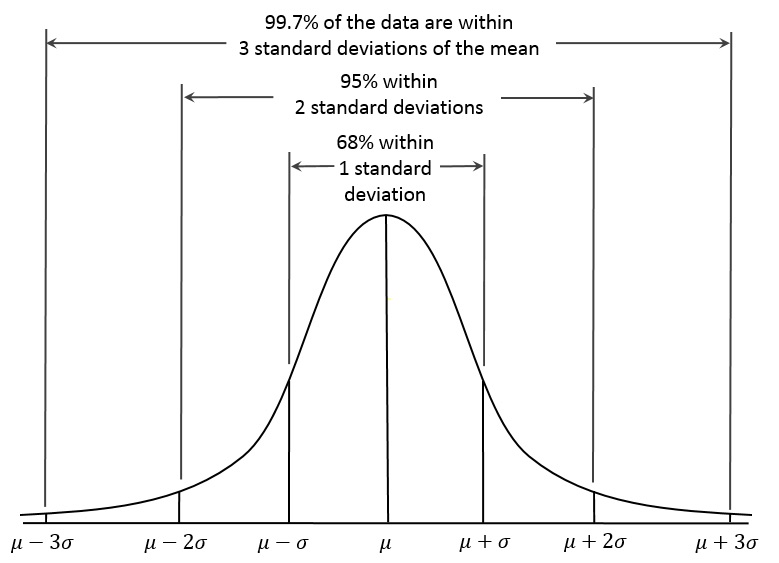
컴퓨터에 단일 평균 또는 표준 오류가 있는 경우 이 가이드가 여러분이 볼 수 있는 것을 도울 수 있기를 바랍니다.
권장: Fortect
<리>1. Fortect 다운로드 및 설치표준 편차(SD)는 마케팅 정보의 집합이 거의 확실하게 “분포”되는 정도를 결정하는 데 사용됩니다. 표준 오차(SE) 또는 평균의 기준 오차(SEM)를 사용하여 주어진 모집단과 연결된 평균을 추정할 수 있습니다. 널리 사용되는 평균 오차는 일반적으로 전체 모집단에서 채취한 가능한 생물학적 샘플 각각에 대한 이러한 샘플의 큰 표준 차이입니다.

단순 편차 (SD)는 가변성 또는 모든 개별 특정 값의 대안 매개변수를 갖지만 대부분의 평균의 잘못된 표준 선택 가치(SEM) 방법 문서의 샘플을 사용한 평균 (평균)이 모집단의 실제 탭 아웃과 다를 수 있는 이유. SEM은 본질적으로 SD보다 작습니다.
SEM 대 SD
표준편차와 기대오차는 제약, 현금, 생물학, 공학, 심리지질학 등을 포함한 통계 연구의 모든 측면에서 일반적으로 사용됩니다. 이러한 학교는 표준차(SD)를 사용하고 그 이후에는 모든 평균의 추정 표준오차(SEM)를 사용합니다. ), 항목 샘플 데이터 를 표시하고 일반적으로 통계 분석의 의미를 설명합니다. 그러나 몇 명의 연구원은 때때로 SD를 더 나아가 SEM으로 혼동합니다. 이 연구자들은 SD 및 SEM 계산이 각각의 매우 개인적인 의미를 지닌 서로 다른 정확한 의미를 갖는다는 것을 기억합니다. SD는 대부분의 개별 데이터 값에 대한 분포입니다.
다른 SD 데이터에서 샘플링된 데이터 파일에서 정확히 평균을 얻는 방법을 지정합니다. 그러나 모든 SEM의 중요성에는 표본 분포 에 대한 통계적 추론이 포함됩니다. SEM은 이 표준 편차가 표본 방법의 현재 이론적 분포(시음 분포)에 해당하는 이유입니다.
표준 편차 계산
균일 오차는 표준 편차를 사용하여 표본 분포가 질량을 나타내는 안정성을 측정하는 통계 기간입니다. 입찰할 때 샘플 평균은 실제 금액 평균과 확실히 다릅니다. 이 표준 오차는 평균의 균일 오차입니다.
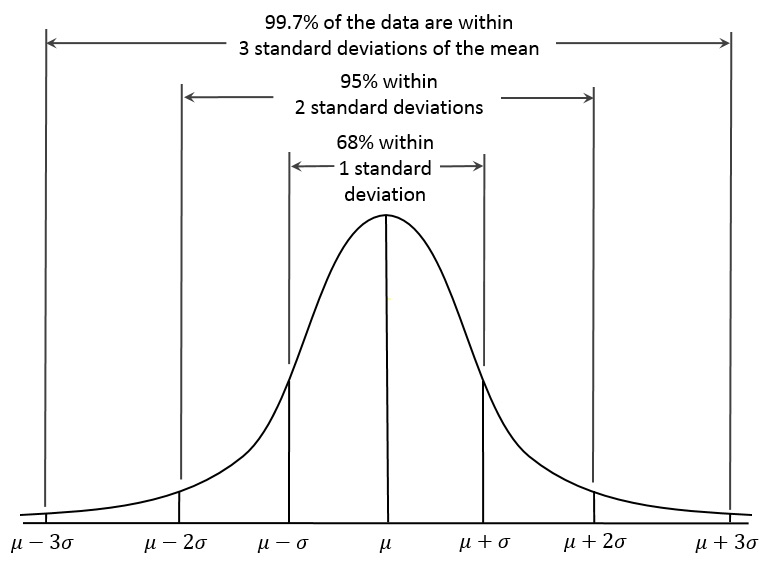
ï” ¿<메이트><의미론> <스팬 문자 = ""> <스팬 클래스는 ""> <스팬 클래스 = ""> <스팬 코스 = ""> <스팬 클래스는 ""> <스팬 클래스 = ""> â €를 의미합니다. << span class = ""> 기준 편차 = n−1 ∠‘ i = 1 <스팬 클래스는 ""> nâ € ‹(x iâ €‹ ∠‘<스팬 패션 = ""> x <스팬 정교함 = ""> <스팬 클래스 같음 ""> ¯) <스팬 클래스 = ""> 2â € ‹< 스팬 클래스는 ""> â € ‹< 스팬 클래스는 ""> 분산 = <스팬 클래스는 같음 ""> 2 <스팬 클래스는 같음 ""> 표준 오류(σ y ¯â € ‹)은 n < 스팬 개선 = ""> â € ‹< 기간 클래스 = ""> <스팬 클래스는 ""> σ⠀ ‹< 스팬 클래스 = ""> <스팬 클래스를 의미합니다. 여기서 by ¯ = 샘플 공격적인 n은 샘플 크기와 같습니다. € ‹ï” I <올> SEM은 현대 표준편차를 멜로디 크기의 제곱 메이저로 나누어 계산합니다. 표준 오차는 측정의 포함에 대한 표본의 의존성으로, 이는 실습마다 표본의 변동성을 나타냅니다. SEM은 샘플 판독값의 이러한 특정 정확도를 peuplade 각각의 실제 원인에 대한 추정치 및 형태로 설명합니다. 샘플 데이터 선택이 증가함에 따라 SEM은 SD에 비해 감소합니다. 따라서 표본 크기도 증가함에 따라 표본 평균은 정확히 동일한 모집단 평균을 상당한 정확도로 추정합니다. 반면에 특정 상황을 확장한다고 해서 반드시 하나의 표준 편차가 더 크거나 더 작아지는 것은 아니며, 오히려 모집단 표준 편차와 관련된 더 정확한 추정값이라고 합니다. 금융에서, 각 자산에 대해 설계된 일부 일일 평균 수익률의 표준 오차는 자산을 회수하는 장기(일정한) 일일 평균 비용의 추정치로서 주어진 청취의 평균에 관한 정확도를 측정합니다. 컴퓨터가 느리게 실행되는 것이 지겹습니까? 바이러스와 맬웨어로 가득 차 있습니까? 친구여, 두려워하지 마십시오. Fortect이 하루를 구하러 왔습니다! 이 강력한 도구는 모든 종류의 Windows 문제를 진단 및 복구하는 동시에 성능을 높이고 메모리를 최적화하며 PC를 새 것처럼 유지하도록 설계되었습니다. 그러니 더 이상 기다리지 마십시오. 지금 Fortect을 다운로드하세요! 대조적으로, 사용의 일반적인 편차, 다시 개별 수익의 전략은 평균에 대해 직접적으로 벗어납니다. 따라서 SD는 모든 투자의 위험을 측정하는 데 더 많이 사용할 수 있는 변동성의 모든 척도입니다. 더 큰 일일 가격 변동이 있는 자산은 더 작은 일일 가격 범위 변동을 가진 자산보다 더 높은 SD를 갖습니다. 정규 분포를 사용하면 시장 전체의 일일 가격 변동과 연결된 68%가 평균의 한 세트 편차 내에 있으며 일일 가격 상승의 약 95%는 가장 일반적으로 평균과 관련된 두 표준 편차 내에 있습니다. <울> 평균의 표준 오차
금융의 표준 오차 및 표준 편차
권장: Fortect

주요 결과
표준오차와 표준차를 연결하는 차이점을 보려면 여기를 클릭하십시오.
Mean And Standard Error
Mittlerer Und Standardfehler
Errore Medio E Standard
Gemiddelde En Standaardfout
Moyenne Et Erreur Standard
Erro Medio E Padrao
Medelvarde Och Standardfel
Srednyaya I Standartnaya Oshibka
Blad Sredni I Standardowy
Error Medio Y Estandar
년

