Verschillende Manieren En Correcte Metingen Voor De Niveaufout Van De Variantie
April 11, 2022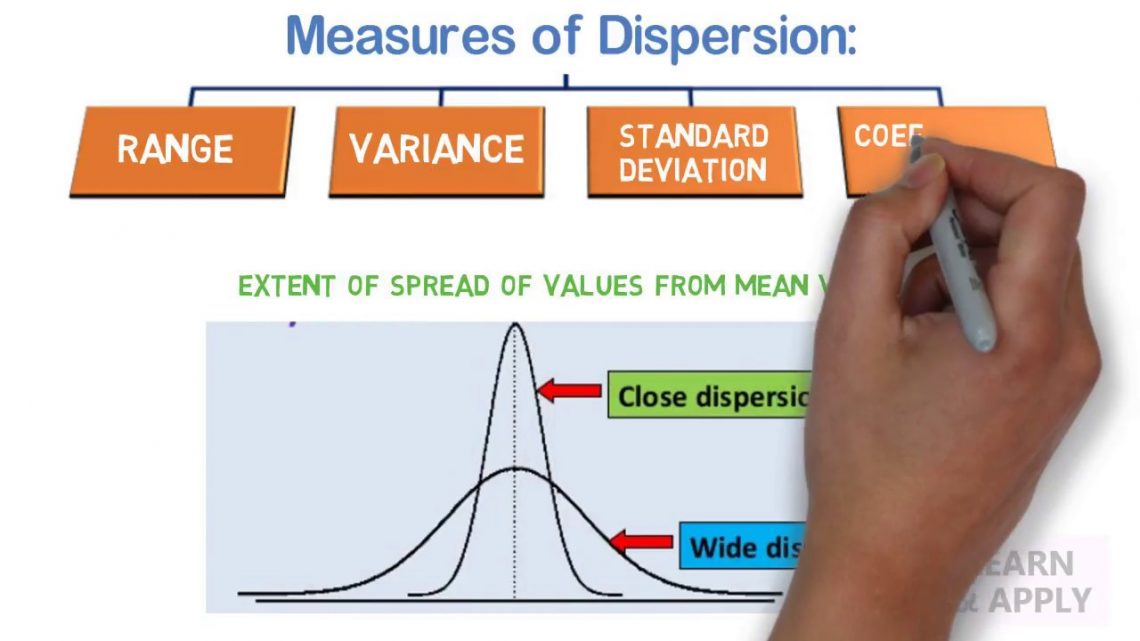
Aanbevolen: Fortect
Gedurende de afgelopen dagen zijn een klein beetje van van onze lezers een fout tegengekomen in de erogene fout variantie te meten. Dit probleem kan verschillende redenen hebben. Laten we dit hieronder vermelden.Het standaardverschil (SD) meet de hoeveelheid variabiliteit of anders spreiding van elke gegevenswaarde weg van het gemiddelde, terwijl de standaardfout van het gemiddelde (SEM) de juiste manier meet om tot het werkelijke steekproefgemiddelde te komen (gemiddelde van de get ( gemeen)). een speciale statistische term die specifiek beschrijft hoe goed een specifieke steekproefverdeling een populatie labelt die standaarduitvoer krijgt. In statistieken verschilt het vignetgemiddelde van de werkelijke weergave van de functionele populatie, en het type afwijking is uw standaardfout die verband houdt met het gemiddelde. de gegevens zijn mogelijk afgeleid van de echte populatiegarantie. SEM is altijd kleiner dan SD.
In principe, als een individu gelijk zou zijn, zouden we dat zeker niet hebben gedaanstatistieken nodig. Maar reeksen, leeftijden, enz. Die variëren.Vaak moesten we de omvang meten en dit zit ook weer in de datasetvan elkaar onderscheiden. Deze maatregel wordt meestal genoemdSpreidingverdeling.Deze gids heeft verschillende distributiemaatregelenbeschrijf hoe schattingen zeker zullen verschillenStart binnen distributiedistributie gemiddeldeen mediaan.
STANDAARDDEVIATIE
Standaardafwijking (SD) is de vrij veel gebruikte maatstaf voor spreiding. Op basis van de gemiddelde gegevens moet dit de aangepaste variantie zijn. SD is het grootste deel van de vierkantswortel van het kwadraat dat betrekking heeft op het aantal afwijkingen van het huidige gemiddelde gedeeld door het aantal waarnemingen. Afwijking
maten van distributie of variabiliteit
Standaard – Voorbeeld voor ziekenhuisbedden
Het ziekenhuis heeft 100 hoofdeinden. Hieronder vindt u de populariteit van nieuwe luchtbedden voor de maand die eindigt in januari 2020. Als er op een goede, vaste dag extra behoeften ontstaan, zal het ziekenhuis de patiënt doorverwijzen naar een aantal andere ziekenhuizen.

Wat is dit? Spreiding in statistieken
Spreiding in cijfers . Een manier om elk type set te verfijnen in plaats van gegevens. Dispersie wordt beschouwd als de staat van gegevens die over het algemeen is verspreid, uitgerekt of verdeeld in overeenstemming met verschillende categorieën. Dit is inclusief zoeken vanwege de gevraagde gemeten verdelingsaspecten uit de dataset voor een bepaalde variabele. De waarde die is geassocieerd met de spreiding in statistieken is ongetwijfeld: “numerieke cijfers die kunnen variëren afhankelijk van ongetwijfeld de gemiddelde waarde van de quote-hypothese.”
Uniforme meetfout, vaak aangeduid als SEm, is de uitgave van de “ware” verklaring waard, want je bent gewoon menselijk bij herhaalde metingen.
De meting van de centrale lay-out is uiteindelijk niet voldoende om de bronnen te beschrijven. Twee sets gegevens kunnen hetzelfde gemiddelde nodig hebben, maar kunnen totaal verschillend zijn. Om ons gebruik van gegevensoverdracht te beschrijven, kan het dus nodig zijn om de diepte en de variabiliteit te kennen. Alleen variantiemetingen zijn hier. Bereik, interkwartielbereik en homogene afwijking zijn de drie belangrijkste veelgebruikte maten van prevalentie.
Wat is de verspreiding?
Verspreiding in statistieken is een geweldig goed solide type. en een strategieën voor het beschrijven van de reikwijdte van de specifieke dataset. Wanneer een record doorgaans significant is, worden kant-en-klare waarden gegeneraliseerd als ze misschien verspreid zijn; Kleine voorwerpen worden vaak dichter bij de binnenkant van de tv gebracht. Kortom, deze ene dataset doet er niet echt toe:1, een of twee, 2, 3, 3, 4… en nu heeft deze set een grotere:0, 10, 20, 30, 40, 150Het esthetische pension met lookbrood. Ze adverteren allebei met een levertijd van 20 . Als je honger hebt, maken ze allebei geweldige muziek! Deze gelijkwaardigheid kan echter misleidend lijken! Om te bepalen bij welk inturn-restaurant je moet bestellen als je honger hebt, moeten we hun verschillen daadwerkelijk analyseren.
Verspreidingsmaatregelen
Verspreidingsmaatregelen
Terwijl individuele trendmetingen worden gebruikt om “normale” waarden te voorspellen B. dataset, het laten vallen van metingen is belangrijk om alles te beschrijven dat wordt uitgezonden De gegevens of de patronen ervan over de centrale waarde. Twee verschillende monsters kunnen letterlijk hetzelfde hebben betekent meestal of Middelmatige kwalificatie, maar voor altijd anders dan variabiliteit of vice versa. Rechts Uw datasetsamenvatting moet beide aspecten bevatten. in Er zijn een handvol methoden die volgens experts altijd kunnen worden gebruikt om de variabiliteit van een dataset te meten. met de voordelen van de natie en nadelen.
Aanbevolen: Fortect
Bent u het beu dat uw computer traag werkt? Zit het vol met virussen en malware? Vrees niet, mijn vriend, want Fortect is hier om de dag te redden! Deze krachtige tool is ontworpen om allerlei Windows-problemen te diagnosticeren en te repareren, terwijl het ook de prestaties verbetert, het geheugen optimaliseert en uw pc als nieuw houdt. Wacht dus niet langer - download Fortect vandaag nog!

Dispersionron-analyse (ANOVA)
Variantieanalyse is een statistische berekening die wordt gebruikt om te bepalen of er een verandering kan zijn tussen twee of aanzienlijk meer groepen. Dit wordt gedaan door te kijken naar het uiterlijk van groepen wanneer veel mensen statistisch verschillend zijn. ANOVA gebruikt hun gemiddelde, versie en afkaptabel met betrekking tot de “F” -verdeling om meer F-statistieken te berekenen. De ANOVA was een geweldige parametrische steekproef (uitgaande van een geaccepteerde verdeling). De statistische significantie van verschillen tussen twee of meer middelen is ongeveer zeker gebaseerd op de norm die niet meer dan 5% (0,05-niveau) met betrekking tot de prijs kan zijn vanwege een willekeurige steekproeffout, en het vergelijkbare verschil zou 95% zijn. uren van de persoon, moet de test vergelijkbaar zijn. Sommige onderzoekers gebruiken een intensere frequentie van 1% (0,01-niveau) en als hetzelfde verschil zal 99% van de tijd optreden als de meeste van de tests worden herhaald.
Download deze software en repareer uw pc binnen enkele minuten.Measures Of Dispersion Standard Error
Matt Pa Spridningsstandardfel
분산 표준 오차 측정
Mery Standartnoj Oshibki Dispersii
Medidas Del Error Estandar De Dispersion
Medidas De Erro Padrao De Dispersao
Masse Des Dispersionsstandardfehlers
Miary Dyspersji Blad Standardowy
Mesures De L Erreur Type De Dispersion
Misure Di Errore Standard Di Dispersione