
Jądro Qla2xxx 12-krokowe Wskazówki
September 18, 2021
Może pojawić się komunikat o błędzie informujący, że jądro to qla2xxx. Istnieje kilka kroków, które możesz wykonać, aby rozwiązać ten problem. Omówimy to za minutę.
Zalecane: Fortect
Środowisko
- Red Hat Enterprise Linux (RHEL)
- Obszar przechowywania FC
Problem
Następujące wiadomości przeszukują dzienniki użytkowników:
Zalecane: Fortect
Czy masz dość powolnego działania komputera? Czy jest pełen wirusów i złośliwego oprogramowania? Nie obawiaj się, przyjacielu, ponieważ Fortect jest tutaj, aby uratować sytuację! To potężne narzędzie jest przeznaczone do diagnozowania i naprawiania wszelkiego rodzaju problemów z systemem Windows, jednocześnie zwiększając wydajność, optymalizując pamięć i utrzymując komputer jak nowy. Więc nie czekaj dłużej — pobierz Fortect już dziś!
- 1. Pobierz i zainstaluj Fortect
- 2. Otwórz program i kliknij „Skanuj”
- 3. Kliknij „Napraw”, aby rozpocząć proces naprawy

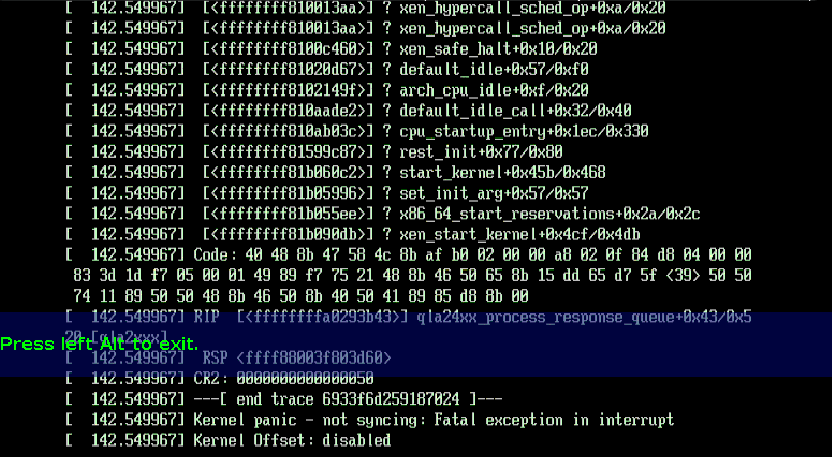
8. 11:56:36 Dec Rdzeń: e: brand 20070203, stały rozmiar bufora 32768, s i9000 / g 256 segmentówSzósty grudnia 11:56:36 Rdzeń: st 0: 0: 10: zero: Dołączony wpis SCSI st75 grudnia 11:56:36 rdzeń: st7: spróbuj bezpośredniego I kontra O: oczywiście (wyrównanie 512B)5 grudnia, 15:46:30 Rdzeń: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): Wydano anulowanie przejęcia - 1 2003 10fb.15 grudnia: 46:41 Rdzeń: qla2xxx 0000: lipiec: 00.0: scsi (0: 10: 0): Odrzuć wydane polecenie - 1 dedykowany 2002 10fb.8 grudnia 15:46:41 Jądro: qla2xxx 0000: 06: 00.0: scsi (0: dziesięć: 0): RESETOWANIE URZĄDZENIA WYKONANE.9 grudnia 15:46:41 Kernel: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): POMYŚLNY RESET URZĄDZENIA.8 grudnia 15:46:52 Kernel: qla2xxx 0000: lato: 00.0: scsi (0: 10: 0): Cofnij zatwierdzone polecenie - 1 2005 10fb.Ważne w grudniu 15:46:52 Jądro: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): RESETOWANIE CYKLU WYKONANE.8 grudnia 15:46:52 Kernel: qla2xxx 0000: 06: 00.0: LOOP DOWN jest na 0 (0 0).15 grudnia: 46:57 Kernel: qla2xxx 0000: 06: 00.0: PĘTLA wykryta do (8 Gbps).7 grudnia 15:47:18 Core: qla2xxx 0000: sierpień: 00.0: qla2xxx_eh_bus_reset: Adaptacja powiodła się3 grudnia 15:47:39 Rdzeń: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): Anuluj typ wydanego polecenia - 1 '03 10fb.2 grudnia 15:47:39 Rdzeń: 0000: 06: 50 qla2xxx.0: scsi (0: 10: 0): RESETOWANIE ADAPTERA ZAKOŃCZONE.8 grudnia, 15:47:39 Core: 0000: 06: 00 qla2xxx.0: Wykonaj odzyskiwanie wywołane przez błąd dostawcy usług internetowych - ffff810139dd44f8 ' =.9 grudnia 15:47:45 Rdzeń: qla2xxx 0000: maj: 00.0: wykryto pętlę (8 Gbps).1 grudnia 15:47:47 qla2xxx Kernel: 0000: 06: 00.Qla2xxx_eh_host_reset: 0: Resetowanie powiodło się15 grudnia: 48: 2007 Rdzeń: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): Odrzuć podane polecenie - 1 2000 10fb.Dec main, 15:48:08 Kernel: saint 0: 0: ten: 0: scsi: Urządzenie odłączone - w ogóle nie jest gotowe po rozwiązaniu problemuGrudzień główny 15:48:08 Core: st 0:0:10:0: Idealne polecenie timeout, oczekiwane 14000 sek.Grudzień ważne, 15:48:08 Kernel: st7: błąd 6080000 (zalecane bt 0x0, taksówkarz British Telecom 0x6, host bt 0x8).
Rozdzielczość
- Skontaktuj się z dostawcą pamięci masowej, aby znaleźć rozwiązanie.
- Powtarzane i ciągłe próby odzyskania dostępu do określonego urządzenia kończą się niepowodzeniem. Tak więc mechanizm zdalny jest uważany za autonomiczny.
- Wystąpił błąd podczas wykonywania prac ogrodniczych w sieci SAN. Obejściem w niektórych przypadkach awarii było wykluczenie automatycznego połączenia również prędkości kanału i podjęcie decyzji o ustawieniu stałej prędkości FC na 4 GB zamiast 8 GB.
- Sprawdź również, czy jest to spowodowane usuwaniem/odłączaniem urządzeń pamięci masowej od nowego serwera, który nie jest używany.
Powód
15 grudnia: 46: 30 7 Rdzeń: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): Odrzuć wydane polecenie - 1 2002 10fb. [2] multiple dec 15:46:41 Kernel: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): Cofnij wydane polecenie specyficzne, które pomoże 2002 10fb. [3]akcje Grudzień 15:46:41 Jądro: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): RESETOWANIE URZĄDZENIA WYKONANE. [3]akcje 15 grudnia: 46:41 rdzeń: qla2xxx 0000: maj: 00,0: scsi (0: 10: 0): POMYŚLNIE ZRESETUJ URZĄDZENIE. [3]Numer grudnia 15:46:52 Rdzeń: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): Anuluj polecenie dało - oczywiście 2002 10fb. [5]11.12. 15:46:52 Jądro: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): RESETOWANIE CYKLU WYKONANE. [5]5 grudnia 15:46:52 Kernel: qla2xxx 0000: sierpień: 00.0: LOOP DOWN wykrył trzy (0 0). [5]8 grudnia 15:46:57 Rdzeń: qla2xxx 0000: 06: 00.0: LOOP Wykrywanie akcji w górę (8 Gb/s). [5]10 grudnia 15:47:18 Core: qla2xxx 0000: 06: 00.0: qla2xxx_eh_bus_reset: Adaptacja powiodła się [5]Grudzień para 15:47:39 Core: 0000: 06: 00 qla2xxx.0: scsi (0: 10: 0): Cofnij podane polecenie - 1 2004 10fb. [6]Kwota grudnia 15:47:39 Idraw: 0000: 06: podwójne zero qla2xxx.0: scsi (0: 10: 0): RESETOWANIE ADAPTERA ZROBIONE. [6]8 grudnia 15:47:39 Core: 0000: 06: 00 qla2xxx.0: Wykonaj profesjonalny błąd medyczny - oznacza ffff810139dd44f8 ha. [6]8 grudnia 15:47:45 Kernel: qla2xxx 0000: 06: 00.0: PĘTLA wykryta na dużej wysokości (8 Gbps). [6]5.gru. 15:47:47 qla2xxx Core: 0000: 06: 00.0: qla2xxx_eh_host_reset: Adaptacja powiodła się [6]10 grudnia, 15:48:08 Rdzeń: qla2xxx 0000: 06: 00.0: scsi (0: 10: 0): Cofnij wydane wymaganie - 1 2005 10fb. [7]8-10 grudnia 15: 48: 08 Jądro: st zero: 0: 10: 0: scsi: urządzenie główna ulica - nie jest gotowe po rozwiązaniu problemu [7]8 grudnia, 15:48:08 Rdzeń: st 0: 8: 10: 0: Czas i rozkazy, spodziewane 14000 firm [1]
- [1] Niektóre aborcje są spowodowane opóźnieniem; ekstremalny powód wbudowanej obsługi błędów jest wyświetlany tylko wtedy, gdy cała główna praca na rynku powtórzeń i odzyskiwania dla danego urządzenia działa tylko dłużej. Jakie były okoliczności w tym pojedynczym przypadku, więc wszystkie kategoryczne przyczyny problemu to z pewnością limit czasu sprzętowego wynoszący 14000 mało czasu tylko dla polecenia I / O dla tego konkretnego urządzenia.
- [2] Pierwszym poziomem dotyczącym obsługi błędów jest po prostu wycofanie tego własnego io i częste powtarzanie wyplatania kapłanów.
- [3] Duplikat io całkowicie przestaje działać, więc jest usuwany i podejmowany jest drugi krok resetowania samej korekcji błędów: dekoder. Reset urządzenia zakończy się sprawnie, a bieżące I/O zostanie powtórzone (przesłane do jednego sprzętu).
- [4] Ponowna próba nie powiodła się z tyłu. Trzecim błędem odzyskiwania kroku będzie zresetowanie celu zapisu. Nie wszystkie karty HBA pamięci masowej obsługują prawie każdą z funkcji głównych resetowania na poziomie docelowym i zostaną zignorowane, jeśli nie będą obsługiwane, tak jak w tym przypadku.
- [5] Ponieważ re-I/O nie powiodło się i kolejny krok resetu) (cel nieosiągalny, opcje czwarty krok rozwiązywania problemów jest faktycznie zaimplementowany: reset magistrali (RESET PĘTLI w konkretnym przypadku jest taki sam jak reset autokaru mci) – turysta połączenie magistrali może zostać przerwane i ponownie nawiązane, głównie dlatego, że można to zobaczyć przez określoną pętlę downstream / upstream. Resetowanie magistrali powiodło się i dodatkowa próba zostanie wykonana z io (wysłana do komputera dla Ciebie).
- [6] Ponowna próba nie powiedzie się, jeśli. Wykonywany jest czwarty krok i przetrwanie, związany z odzyskiwaniem po awarii: zresetuj adapter tak, aby wyzerował. Jeśli jest profesjonalna, to może io będzie na razie powtarzane częściej (wyślij do sprzętu).
- [7] Powtarzane io nie działa po raz drugi. Po wyczerpaniu wszystkich prób naprawy sprzętu, a mimo to mój typ I / O nie działa poprawnie, urządzenie bez wątpienia nie będzie połączone z siecią społecznościową i zostanie wyświetlona przyczyna niemożności. W tym stanie głównym powodem jest odpowiedni limit czasu.
Oto 5 standardowych instrukcji dotyczących eskalacji inicjatyw dotyczących rozwiązywania problemów ze Scsi:
- Anuluj, spróbuj ponownie
- Upuść urządzenie i zresetuj, spróbuj ponownie
- Upuść i zresetuj docelowy obszar garażu, spróbuj ponownie
- Wyjdź i pomnóż autobus, spróbuj ponownie
- Anuluj i zresetuj ustawienia adaptera, spróbuj ponownie.

Tak więc, po pięciu próbach i odpowiedniej serii prób przywrócenia produktywnej komunikacji w celu przywrócenia konkretnego urządzenia, wszystkie próby pomocy w jego utrzymaniu zakończyły się niepowodzeniem. W danym momencie każdy z naszych systemów oferuje niewiele innego wyboru, ale ma potencjał, aby wyłączyć urządzenie, aby uniknąć takiego wysiłku w przyszłych projektach I/O. Ograniczenie przyszłych prób zapobiega zakłócaniu działania innych urządzeń na tej samej magistrali po ponownym uruchomieniu magistrali i adaptera oraz wpływa na wszystkie urządzenia na tej samej karcie HBA/centrali.
Czynności diagnostyczne
- Może to ujawnić szereg dylematów: HBA, SAN lub pasmo ST. Sprawdzaj łączność z siecią SAN za każdym razem, gdy pamięć masowa.
To rozwiązanie najlepiej można nazwać częścią programu Red Hat Fast Track Articles, który posiada dużą bibliotekę rozwiązań opracowanych przez Red Engineers, które bez wątpienia pomogą naszym klientom . Aby dać komukolwiek potrzebną wiedzę, ponieważ dziś, gdy staje się ona dostępna do sprzedaży, artykuły można przesyłać w prymitywnej i nieedytowanej formie.
Pobierz to oprogramowanie i napraw swój komputer w kilka minut.
Qla2xxx Kernel
Qla2xxx Kernel
Qla2xxx Kernel
Qla2xxx Kernel
Noyau Qla2xxx
Qla2xxx 커널
Kernel Qla2xxx
Qla2xxx Karnan
Yadro Qla2xxx
Kernel Qla2xxx

