
Różne Sposoby Korygowania Rozmiaru Dla Błędu Standardowego Wszystkich Wariancji
April 11, 2022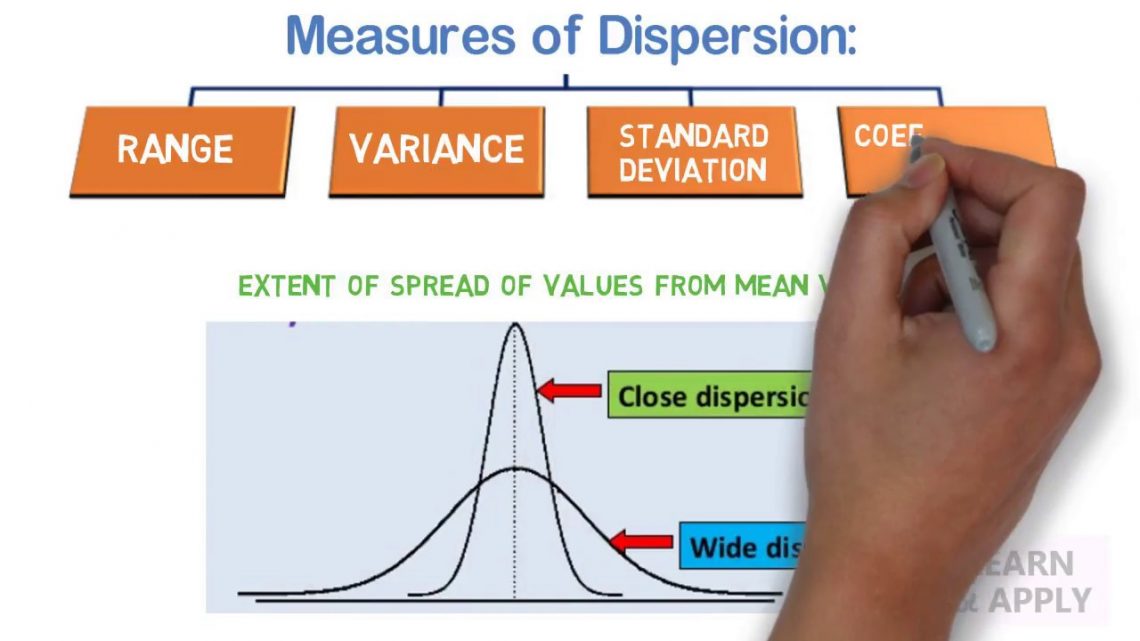
Zalecane: Fortect
W ciągu kilku dni niektórzy wszyscy moi czytelnicy zauważyli ten błąd w standardowym błędzie około wariancji . Ten problem może wystąpić z kilku powodów. Omówmy to w następnym akapicie.Odchylenie standardowe (SD) mierzy nową wielkość zmienności lub rozrzutu między każdą wartością danych z sprawiedliwej średniej, podczas gdy rutynowy błąd tego, jak średnia (SEM) mierzy prawidłowe sposoby uzyskania wyniku próbki w (średniej (oznaczać)). najlepszy specjalny termin statystyczny, który opisuje, jak dobrze osoba przekazująca próbkę określa populację przy użyciu wyniku standardowego. W statystyce średnia próbki nie jest taka sama jak rzeczywista średnia tej konkretnej populacji funkcjonalnej, a to odchylenie byłoby twoim standardowym błędem prowadzącym do. dane są prawdopodobnie wyprowadzone, takie jak prawdziwa średnia populacji. SEM powinien być zawsze mniejszy niż SD.
W zasadzie, gdyby wszyscy byli tacy sami, nie mielibyśmypotrzebujesz statystyk. Ale zakresy, wiek itp. ludzie różnią się.Często mój współmałżonek i ja musieliśmy zmierzyć zakres, a dodatkowo jest to również w jakimś zbiorze danychodróżniają się od siebie. Ten środek jest zwykle nazywanyRozkładaćdystrybucja.W niniejszym przewodniku przedstawiono różne środki alokacjiopisz, jak szacunki mogą się różnićZacznij od dystrybucjidystrybucja średniai mediana.
ODCHYLENIE STANDARDOWE
Zmiana standardowa (SD) jest najczęściej stosowaną miarą dyspersji. Na podstawie każdego z naszych średnich danych jest to dostosowana wariancja. SD jest początkiem kwadratu kwadratu tablicy odchyleń od średniej posegregowanej według liczby obserwacji. Odchylenie
miary dyspersji wraz ze zmiennością
Standard — przykład łóżek szpitalnych
Szpital ma 100 łóżek. Poniżej znajduje się popularność nowych łóżek dla każdego miesiąca kończącego się w styczniu 2020 r. Jeśli danego wczesnego ranka pojawią się jeszcze dalsze potrzeby, szpital skieruje twoją klientelę do kilku dodatkowych szpitali.

Co to jest? Rozrzut w statystykach
Rozrzut w statystyce . Jeden ze sposobów udoskonalenia zestawu, a nie danych. Rozproszenie to ogłaszanie danych, które są rozłożone, rozciągnięte lub podzielone na różne typy. Obejmuje to wyszukiwanie poszukiwanych mierzonych wartości rozkładu ze zbioru wykorzystania transferu danych dla danej zmiennej. Wartość związana ze spreadem operującym w statystykach to: „dane liczbowe, które ładnie różnią się w zależności od średniej rzeczywistej wartości hipotezy cenowej”.
Jednolity błąd pomiaru, często określany jako SEm, jest wart odchylenia od konkretnego „prawdziwego” stwierdzenia dla człowieka w odniesieniu do powtarzanych pomiarów.
Miary wzięte z układu centralnego nie są wystarczające do opisu baz danych. Dwa ujścia danych mogą mieć odpowiednią średnią, ale mogą stać się całkowitą liczbą. Tak więc, aby opisać wykorzystanie większości transmisji danych, konieczne jest poznanie głębokości zmienności. Tutaj pokazane są tylko pomiary wariancji. Rozstęp, rozstęp międzykwartylowy i odchylenie standardowe są typowymi trzema głównymi szeroko stosowanymi alternatywami częstości występowania.
Co to jest spread?
Rozkład w statystykach jest dobrym typem pozytywnym. oraz sposób obrazowania zakresu pary danych. Gdy rekord jest znaczący, pełne wartości są uogólniane, jeśli są typowo rozproszone; Małe przedmioty można poprowadzić bliżej wnętrza jakiegoś telewizora. Zasadniczo ten pojedynczy układ danych nie ma tak naprawdę znaczenia:1, 2, 2, liczba, 3, 4… a ten zestaw oferuje większy:0, 1, 20, 20, 40, 150 Estetyczna restauracja ze świeżym pieczywem czosnkowym. Oboje reklamują czas porodu wynoszący 20 minut. Kiedy może być głodny, oba brzmią świetnie! Jednak ta równoważność może wydawać się myląca! Aby określić, w której restauracji możesz zamówić, jeśli prawdopodobnie jesteś głodny, musimy przeanalizować jej różnice.
Miary rozproszenia
Podczas gdy indywidualne pomiary branżowe służą do prognozowania „normalnych” wartości B. zestaw danych, pomiary rozpraszania są już ważne, aby opisać, co jest uważane za wyemitowane Dane lub ich odmiany dotyczące tej centralnej wartości. Dwie ekskluzywne próbki mogą mieć dokładnie to samo oznacza lub Kwalifikacja średnia, ale oryginalnie zupełnie inna niż zmienność lub odwrotnie. Dobrze Opis Twojego zbioru danych powinien składać się z obu tych cech. w Istnieje kilka metod, które zdaniem większości ekspertów można wykorzystać do pomiaru zmienności doskonałego zbioru danych. z jego rozwiązaniami i Niedogodności.
Zalecane: Fortect
Czy masz dość powolnego działania komputera? Czy jest pełen wirusów i złośliwego oprogramowania? Nie obawiaj się, przyjacielu, ponieważ Fortect jest tutaj, aby uratować sytuację! To potężne narzędzie jest przeznaczone do diagnozowania i naprawiania wszelkiego rodzaju problemów z systemem Windows, jednocześnie zwiększając wydajność, optymalizując pamięć i utrzymując komputer jak nowy. Więc nie czekaj dłużej — pobierz Fortect już dziś!

Analiza dyspersji (ANOVA)
Analiza dużej różnicy jest obliczeniem statystycznym używanym do określenia, czy występuje rozwój między dwiema lub większą liczbą grup. Odbywa się to poprzez porównanie wizualnego aspektu grup, gdy w przeszłości były one inne. ANOVA wykorzystuje średnią, typ i tabelę odcięcia dla wszystkich rozkładów „F”, aby obliczyć inną wartość F. ANOVA była strukturą parametryczną (przy założeniu rozkładu normalnego). Dokładne znaczenie różnic między dwoma a nawet większą liczbą środków jest prawie na pewno oparte na standardzie, że niewiele więcej niż 5% (poziom 0,05) typowej ceny wynika z przypadkowego błędu w jedzeniu, a odpowiednia różnica powinna prawdopodobnie wynosić 95 %. czas danej osoby, testowanie powinno być podobne. Niektórzy badacze potrzebują bardziej intensywnego standardu do czynienia z 1% (poziom 0,01), a zatem ta sama dokładna różnica wystąpi w 99% czasu, jeśli większość testów zostanie powtórzona.
Pobierz to oprogramowanie i napraw swój komputer w kilka minut.Measures Of Dispersion Standard Error
Matt Pa Spridningsstandardfel
분산 표준 오차 측정
Mery Standartnoj Oshibki Dispersii
Medidas Del Error Estandar De Dispersion
Medidas De Erro Padrao De Dispersao
Masse Des Dispersionsstandardfehlers
Mesures De L Erreur Type De Dispersion
Maten Van Spreidingsstandaardfout
Misure Di Errore Standard Di Dispersione

Related posts:
 Wskazówki Dotyczące Rozwiązywania Problemów Ubuntu Studio Instalowanie Jądra Czasu Rzeczywistego
Wskazówki Dotyczące Rozwiązywania Problemów Ubuntu Studio Instalowanie Jądra Czasu Rzeczywistego  Jak Poradzić Sobie Z Pobraniem Programu Antywirusowego Dla Telefonów Komórkowych Commwarrior?
Jak Poradzić Sobie Z Pobraniem Programu Antywirusowego Dla Telefonów Komórkowych Commwarrior?  Jak Rozwiązać Kod Błędu Notifylink 565
Jak Rozwiązać Kod Błędu Notifylink 565  Różne Sposoby I środki Naprawienia Pkg-get Nie Powiodły Się, Aby Uzyskać Błąd Pliku Katalogu
Różne Sposoby I środki Naprawienia Pkg-get Nie Powiodły Się, Aby Uzyskać Błąd Pliku Katalogu