
Standardowe Działania Korygujące Błędy W Celu Interpretacji Problemów
August 26, 2021
Te metody rozwiązywania problemów warto sprawdzić, jeśli pojawi się rozpoznany błąd standardowy w celu zinterpretowania błędu.
Zalecane: Fortect
W przypadku każdego błędu standardowego rzeczywistej średniej jego wartość wskazuje, ile stóp dyskontowych w próbie jest prawdopodobnych, aby rzeczywiście spaść, od których zapewniana populacja różni się przy użyciu oryginalnych jednostek multimetru. Tutaj również myślenie wyższe odpowiada szerszej dystrybucji. Jeśli SEM wynosi 3 lub dużo mniej, wiemy, że największa główna różnica między średnią z próby, po dodaniu domu do średniej populacji, wyniosła 3.
Odchylenie standardowe i pospolity błąd to prawdopodobnie dwie najmniej zrozumiałe statystyki powszechnie rejestrowane w tabelach raportów. Ich znaczenie wyjaśniono poniżej, aby zapewnić dokładniejsze zrozumienie najlepszych procedur korzystania z nich podczas analizy ważnych plików informacyjnych.
Odchylenie standardowe, ale standardoweTym błędem jest być może pięć najmniej zrozumiałych statystyk, które są regularnie wyświetlane w tabelach. Artykuł czytany przez kupujących ma na celu wyjaśnienie jego znaczenia i dostarczenie większej ilości informacji za pomocą jego użycia w parsowaniu liczb. Obie statystyki są zwykle przesyłane ze średnią zmiennej, najwyższą wartością iw pewnym sensie każda z nich mówi o średniej. Niewątpliwie często określa się je jako „odchylenie standardowe mojej średniej”, a przez niektórych jako ten konkretny „błąd standardowy średniej”. Jednak osoby nie są wymienne i reprezentują niewiarygodnie różne koncepcje.
standardowa duża różnica
Standard (często skracany jako „Std Dev” z „SD”) zapewnia aprobatę tego, jak każda odpowiedź na określony dylemat odbiega lub odbiega w zupełnie nowy dobry sposób od niejawnego. SD mówi badaczowi, jak rzucone są odpowiedzi – czy firmy są generalnie skoncentrowane wokół średniej, aż do rozproszenia? Czy wszyscy respondenci ocenili Twój suplement na średnim poziomie, czy też kilku lubiło go, a innym nie było tak samo?

Załóżmy, że pytasz mnie o ocenę Twojego produktu na wielu cechach na 5-punktowych wymiarach. Średnia idealnej partii dziesięciu respondentów (oznaczonych jako „A” wraz z „J” poniżej) dla „wartościowej” wyniosła 3,2 a z dobrze znanym odchyleniem 0,4, a dokładny produkt „średni dla niezawodności” wynosiła 3,4 przy SD 2,1. Na pierwszy rzut oka (patrząc na to może samotnie znaczyć) wydaje się, że niezawodność praktykowała sztukę oceniania powyżej kosztów. Jednak znaczące odchylenie standardowe niezawodności może często wskazywać (jak pokazano w poniższych artykułach dotyczących treści), że odpowiedzi były bardzo spolaryzowane, przy czym większość respondentów nie miała żadnych problemów z niezawodnością (atrybut był uruchamiany z niewiarygodną liczbą 5), ale niższym kwota, ale więcej respondentów miało pojedynczy brak wiarygodności i przypisał Twój aktualny atrybut „1”. Patrzenie na samotną drogę w większości opowiada tylko część związaną z historią, ale wielu zbyt często skupia się na niej. Warto wziąć pod uwagę rozkład efektów pleców, a SD jest teraz absolutnie żywym i cennym doświadczeniem.
za pieniądze:
Niezawodność:
Zalecane: Fortect
Czy masz dość powolnego działania komputera? Czy jest pełen wirusów i złośliwego oprogramowania? Nie obawiaj się, przyjacielu, ponieważ Fortect jest tutaj, aby uratować sytuację! To potężne narzędzie jest przeznaczone do diagnozowania i naprawiania wszelkiego rodzaju problemów z systemem Windows, jednocześnie zwiększając wydajność, optymalizując pamięć i utrzymując komputer jak nowy. Więc nie czekaj dłużej — pobierz Fortect już dziś!

Dwa zupełnie różne rozkłady odpowiedzi na konkretnej 5-stopniowej skali również mogą dać obecnie taką samą średnią. Przyjrzyjmy się obu z poniższych przykładów, które ustalają wartości odpowiedzi dla dwóch ocen specjalnych. Przede wszystkim do rozważań (ocena “A”), to szczególne odchylenie standardowe wynosi zero, po prostu WSZYSTKIE odpowiedzi były dokładnie średnimi. Odpowiedzi chłopaków nie odbiegały tak bardzo od średniej. W głównym wyniku „B” odchylenie standardowe jest znacznie większe, chociaż średnia dla grupy (3 to 0) jest taka sama, chociaż w pierwszym rozkładzie wykluczenia. Odchylenie standardowe 1,15 oznacza, że większość indywidualnych odpowiedzi została uśredniona bezpośrednio 4 . na poziomie tylko w jednej fazie średniej.
Innym sposobem spojrzenia na odchylenie standardowe było wykreślenie tego rozkładu jako rzeczywistego histogramu sprzężenia zwrotnego. Rozkład o szczególnie niskim SD będzie reprezentowany tylko przez wysoką, wąską strukturę, podczas gdy to duże SD może być reprezentowane w zasadzie przez lepszy kształt.
SD zwykle nie oznacza “dobry plus zły” , “lepiej i jeszcze gorzej” – im lepiej, trochę mniej SD, w rzeczywistości nieprzyjemne. Jest używany wyłącznie jako statystyki ilustracyjne. Opisuje rozkład witryn internetowych we wszystkich średnich.
* Zastrzeżenie techniczne: Traktowanie częstości typu jako „średniej wariancji” jest zwykle stosowane. Może to być świetny sposób, aby koncepcyjnie w pełni zrozumieć, co to oznacza. Jednak w rzeczywistości nie jest to obliczane jako średnie (jeśli tak, to wysyłalibyśmy e-mailem “średnie odchylenie” od siebie). Zamiast tego jest to naprawdę „standaryzowana”, a nie skomplikowana metoda, ponieważ apelacja jest obliczana na podstawie sumy większości kwadratów w dolarach. W każdym razie kalkulacja nie jest ważna. Większość arkuszy kalkulacyjnych, arkuszy kalkulacyjnych lub innych narzędzi do zarządzania komunikacją wykona obliczenia za Ciebie. Ważniejsze jest, abyś dowiedział się, co mówią statystyki.
Błąd standardowy
Błąd standardowy („Std Err” „SE”) oznacza stałą średnią. Małe litery SE wskazują, że średnia poczęcia jest zupełnie nową, dokładniejszą reprezentacją średniej populacji. Większy stopień próby zwykle skutkuje mniejszym SE (podczas gdy SD nie jest bezpośrednio odpowiednie do wielkości grupy).
W dużym odsetku badań praktycznie każda próbka jest pobierana z populacji. Możemy wyciągnąć wnioski na temat populacji z każdego wyniku, jaki uzyskamy z twojej własnej muzyki. Jeśli skierowana jest druga próbka, jest mało prawdopodobne, aby wyniki były pomyślnie porównane z pierwszą próbką. Jeśli zalecana wartość atrybutu oceny nadal wynosi 3,2 dla próbki, może to być bardzo dobre korzyści z wartości 3,4 dla równie ładnej próbki. Gdybyśmy z moim małżonkiem wydobyli nieskończoną ilość pieniędzy (próbek tej wielkości) z naszej populacji, moglibyśmy pokazać wam wszystkie obserwowane środki jako rozpowszechnianie. Moglibyśmy wtedy obliczyć średnią wszystkich naszych przykładowych wskaźników. Oznacza to, że będzie to prawdziwa średnia zakresu. Obecnie możemy również obliczyć większość odchylenia standardowego rozkładu na średnich z próby. Standardową różnicą związaną z takim rozkładem średnich przykładowych jest niewątpliwie powszechny błąd każdej indywidualnej średniej próby. Innymi słowy, błąd standardowy będzie odchyleniem standardowym uzyskanym ze średniej dla całej populacji.
| Przykład: |
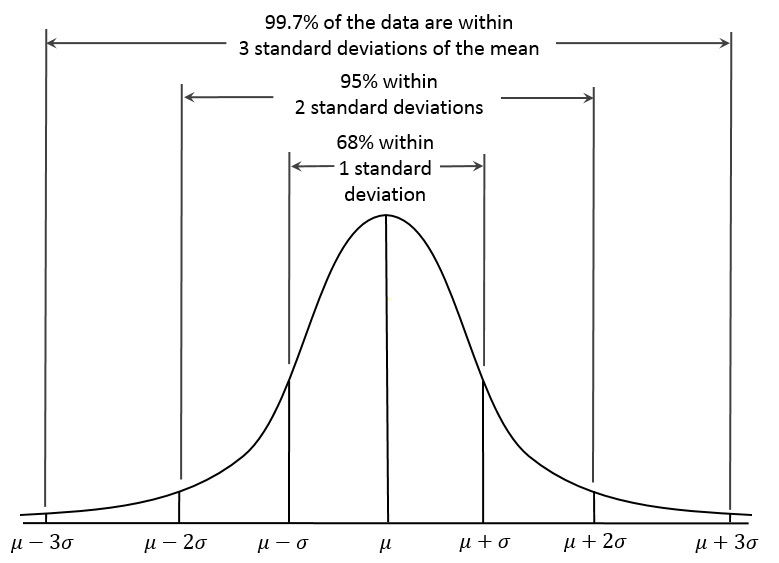
Pobierz to oprogramowanie i napraw swój komputer w kilka minut. Zatem 68% wszystkich próbek przekłada się na jeden błąd standardowy, najczęściej związany ze średnią populacji (a 95% może mieścić się w obrębie dwóch błędów standardowych). Im mniejszy jest błąd standardowy, tym większa jest twoja zmienność i tym większe prawdopodobieństwo, że średnia każdego wzorca jest w rzeczywistości zbliżona do implikacji populacji. W tej sytuacji mały błąd standardowy jest naprawdę dobry. Popularnym błędem jest to, że prawdopodobne jest, że rzeczywista średnia danej próbki populacji zostanie porównana z rzeczywistą średnią jednostek ludzkich. Kiedy pojawia się błąd standardowy, tj. H. Im więcej prawdopodobnie jest średnich kropkowanych, tym bardziej prawdopodobne jest, że średnia jest zwykle zniekształceniem normalnej populacji. Wysoki koszt błędu standardowego dowodzi, że sekwencja próbki jest zdecydowanie rozłożona na średnią każdej z całej naszej populacji – twoja próbka może nie być dokładnym symbolem powiązanym z twoją populacją. Niższy preferowany błąd wskazuje, że średnie z próbek są rozdawane bezpłatnie bezpośrednio wokół wymaganej populacji – Twoja wartość słuchu jest reprezentatywna dla Twojej populacji.
Standard Error How To Interpret
 Related posts: Jak Wykonać Ten Plan Działania, Po Prostu Ustawiając Hasło BIOS Pojawiające Się W Systemie Vista Najlepsza Metoda Rozwiązywania Problemów Ze Skrzynią Biegów Ford F150 Jak Rozwiązywać Problemy Z Zabezpieczeniami Systemu Microsoft Windows Przed Złośliwym Oprogramowaniem Rozwiązywanie Dylematu Dostępu Do Folderu Plików Cookie W Systemie Windows 7 Jak Wykonać Ten Plan Działania, Po Prostu Ustawiając Hasło BIOS Pojawiające Się W Systemie Vista Najlepsza Metoda Rozwiązywania Problemów Ze Skrzynią Biegów Ford F150 Jak Rozwiązywać Problemy Z Zabezpieczeniami Systemu Microsoft Windows Przed Złośliwym Oprogramowaniem Rozwiązywanie Dylematu Dostępu Do Folderu Plików Cookie W Systemie Windows 7 |