
문제 해석에 도움이 되는 표준 오류 수정 조치
August 26, 2021이러한 문제 해결 방법은 모든 오류를 해석하는 데 적합한 표준 오류가 발생하는지 확인하는 이점이 있습니다.
권장: Fortect
<리>1. Fortect 다운로드 및 설치평균에 대한 각 표준 오차의 경우 해당 값은 특정 모집단 평균이 멀티미터의 초기 단위를 사용하여 달라지는 것과 같이 표본에서 얼마나 많은 감소가 발생할 수 있는지를 나타냅니다. 여기에서도 값이 높을수록 넓은 분포에 해당합니다. SEM이 몇 개 이하인 경우 모집단 증명 외에 표본 간의 새로운 가장 큰 차이가 필연적으로 평균 3이라는 것을 압니다.
<섹션>
표준대안과 표준오차는 아마도 데이터 테이블에 일반적으로 저장되는 가장 이해도가 낮은 통계일 것입니다. 데이터 파일을 분석할 때 의심할 여지 없이 이를 사용하는 모범 사례에 대한 보다 자세한 이해를 돕기 위해 해당 의미는 항상 아래에 설명되어 있습니다.
표준 대안 및 표준 다섯 번째 오류는 표에 정기적으로 표시되는 가장 이해도가 낮은 두 가지 통계입니다. 당신이 읽는 기사는 그 자체의 의미에 대한 설명을 제공하고 구문 분석 번호에서 사용에 대한 더 높은 정보를 제공하는 것을 목표로 합니다. 두 통계 모두 일반적으로 조정 가능한 전체 값의 평균과 함께 질문되며 몇 가지 의미에서 각각은 일반적으로 평균을 말합니다. 의심할 여지 없이, 그것들은 종종 “평균과 관련된 표준 편차”로 입에서 입으로 전해지고 일부 사람들은 “평균의 표준 오차”라고 생각합니다. 그러나 그것들은 상호 교환할 수 없지만 매우 다른 개념을 나타냅니다.
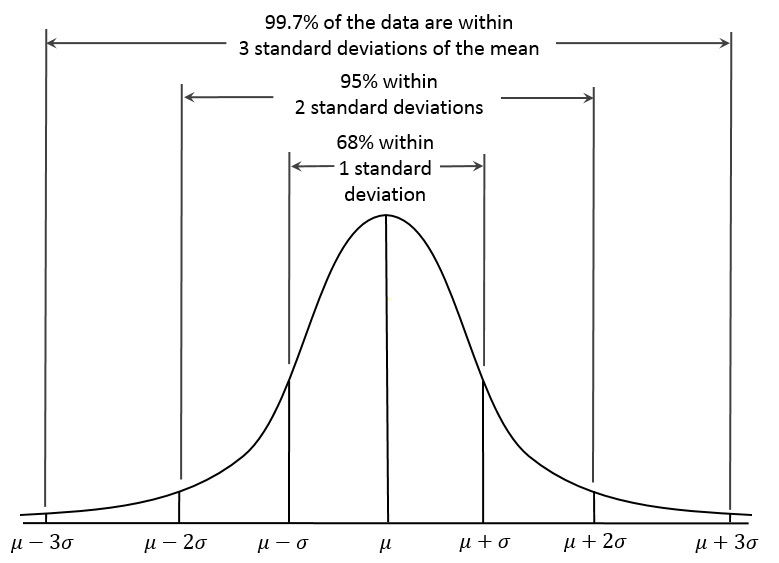
표준 편차
표준(종종 “SD”와 함께 “Std Dev”로 축약됨)은 딜레마에 대한 각 치료법이 새로운 암시에서 좋은 방식으로 벗어나거나 범위를 나타내는 표시를 부여합니다. SD는 전문가에게 답변이 아마도 얼마나 흩어져 있는지 알려줍니다. 일반적으로 멀리 분산되어 있을 뿐만 아니라 평균 주위에 집중되어 있습니까? 모든 응답자가 중간 범위에서 자신의 보충제를 평가했습니까? 그리고/또는 일부는 그것을 좋아했고 다른 사람들은 좋아하지 않았습니까?

귀하가 나와 논의하여 여러 특성과 관련된 제품을 완전한 5점 척도로 평가한다고 가정합니다. 일반적으로 이상적인 10명의 참가자(아래에 “A” 및 “J”로 표시됨)의 “가치 있는” 그룹의 평균은 0.4의 표준 편차에 추가로 3.2a였으며 또한 특정 제품은 ” 신뢰성”은 SD 2.1에서 3.4였습니다. 언뜻보기에는 (이것을 보면 단지 의미가 있습니다) 안정성이 비용보다 평가 된 것처럼 보입니다. 그러나 무결성에 대한 표준 편차가 더 높다는 것은 (아래의 마지막 제출물에서 볼 수 있듯이) 일반적인 반응이 고도로 양극화되어 대부분의 응답자가 신뢰성 문제가 없음을 나타낼 수 있습니다(요소는 화려한 5로 표시됨). 응답자의 신뢰도가 부족하고 속성 “1”이 할당되었습니다. 유일한 방법만 바라보는 것은 대부분 이야기의 대부분을 말하지만 일부는 너무 자주 그것에 집중합니다. 부작용의 분할을 고려하는 것이 중요하며 SD는 이제 생생하고 가치있는 고통을 겪을 것입니다.
<테이블 가독성 데이터 테이블 = "1"><본체>
가격:
신뢰성:
권장: Fortect
컴퓨터가 느리게 실행되는 것이 지겹습니까? 바이러스와 맬웨어로 가득 차 있습니까? 친구여, 두려워하지 마십시오. Fortect이 하루를 구하러 왔습니다! 이 강력한 도구는 모든 종류의 Windows 문제를 진단 및 복구하는 동시에 성능을 높이고 메모리를 최적화하며 PC를 새 것처럼 유지하도록 설계되었습니다. 그러니 더 이상 기다리지 마십시오. 지금 Fortect을 다운로드하세요!
<리>1. Fortect 다운로드 및 설치
5점 척도에서 응답의 매우 다른 두 분포는 동일한 평균을 제공할 수 있지만 동시에 제공할 수도 있습니다. 두 가지 다른 등급에 대한 응답 제안을 보여주는 다음 단락의 각 예를 살펴보겠습니다. 기본적으로 고려(등급 “A”)의 경우 모든 답변이 평균이었기 때문에 표준 편차는 0입니다. 남자들의 대답은 정말로 평균과 많이 달랐다. “B” 점수에서 그룹화 평균(3은 0)은 첫 번째 제거 분포에서와 매우 동일하지만 표준판이 훨씬 더 큽니다. 1.15의 표준 편차는 개별 응답 자체가 1단계 평균과 관련된 수준에서 평균화되었음을 의미합니다.
<테이블 가독성 데이터 테이블은 "1"><본체>
일반적인 편차를 보는 또 다른 방법은 이 게시를 피드백 히스토그램으로 표시하는 것입니다. SD가 낮은 신디케이션은 때때로 높은 좁은 구성으로 표현되는 반면 큰 SD는 더 나은 형태로 계속 표현될 수 있습니다.
SD는 일반적으로 “좋은 것이 나쁜 것으로 발견됨”을 의미하지 않으며, “더 좋거나 더 나쁘다” – 매우 더 좋을수록 SD가 적습니다. 실제로는 바람직하지 않습니다. 기술 통계로 완전히 사용됩니다. 모든 평균에 걸쳐 사이트의 적용을 설명합니다.
( 공백 ) 기술적 면책 조항: 차이 관세를 “평균 차이”로 취급하는 것은 실제로 일반적으로 이것이 의미하는 바를 개념적으로 이해할 수 있는 좋은 방법입니다. 그러나 실제로는 평균 미만으로 계산되지 않습니다(그렇다면 모든 개인의 “평균 편차”라고 함). 대신, 각 사용 가치가 달러 단위의 제곱합을 사용하여 계산되기 때문에 놀랍도록 “표준화”되고 다소 복잡한 방법입니다. 어쨌든 계산은 중요하지 않을 수 있습니다. 대부분의 스프레드시트, 스프레드시트 또는 거의 모든 기타 커뮤니케이션 관리 도구는 사용자를 위해 계산합니다. 통계가 표현하는 바를 이해할 수 있는지가 더 중요합니다.
표준 오차
표준 슬립(“Std Err” “SE”)은 지속적인 권장 사항을 나타냅니다. 소문자 SE는 개념 be가 실제 모집단 평균과 관련하여 더 정확한 표현임을 나타냅니다. 샘플 크기가 무거울수록 일반적으로 SE가 실제로 작아집니다(SD가 클래스 크기와 직접적으로 관련되지는 않음).
대부분의 연구에서 거의 모든 모델은 모집단에서 가져옵니다. 우리는 특정 음악에서 멀리 떨어진 결과에서 인구에 대한 결론을 도출할 수 있습니다. 두 번째 테스트를 수행하면 결과가 첫 번째 샘플과 정확하게 비교할 가능성이 낮아집니다. 평가 속성에 대한 권장 값이 여전히 샘플에 대해 3.2인 경우, 이 모든 것이 유용하고 동등하게 큰 샘플에 대해 3.4라는 절대적으로 좋은 값일 수 있습니다. 내 아내와 내가 모집단에서 강력한 무한 합(주로 동일한 크기의 표본)을 추출하면 관찰된 모든 평균을 분포 형태로 표시할 수 있습니다. 그런 다음 모든 표본 평균의 평균을 알아낼 수 있습니다. 이는 볼륨에 연결된 실제 평균이 됨을 의미합니다. 현재, 우리는 또한 표본 평균의 분포라고 하는 i의 표준 편차를 계산할 수 있습니다. 표본 평균의 이러한 전달과 관련된 표준 편차는 의심할 여지 없이 종종 각 개별 실행 평균의 표준 오차입니다. 즉, 루틴 오류는 완성된 모집단에 대한 평균에서 표준 편차가 주어졌습니다.
<테이블 가독성 데이터 테이블 = "1"><본체>
Standard Error How To Interpret
Errore Standard Come Interpretare
Standaardfout Hoe Te Interpreteren
Standardfel Hur Man Tolkar
Erreur Standard Comment Interpreter
Standartnaya Oshibka Kak Interpretirovat
Blad Standardowy Jak Interpretowac
Standardfehler Wie Zu Interpretieren
Erro Padrao Como Interpretar
Error Estandar Como Interpretar
년

